Anatomy of a Drove Cluster¶
The following diagram provides a high level overview of a typical Drove cluster.
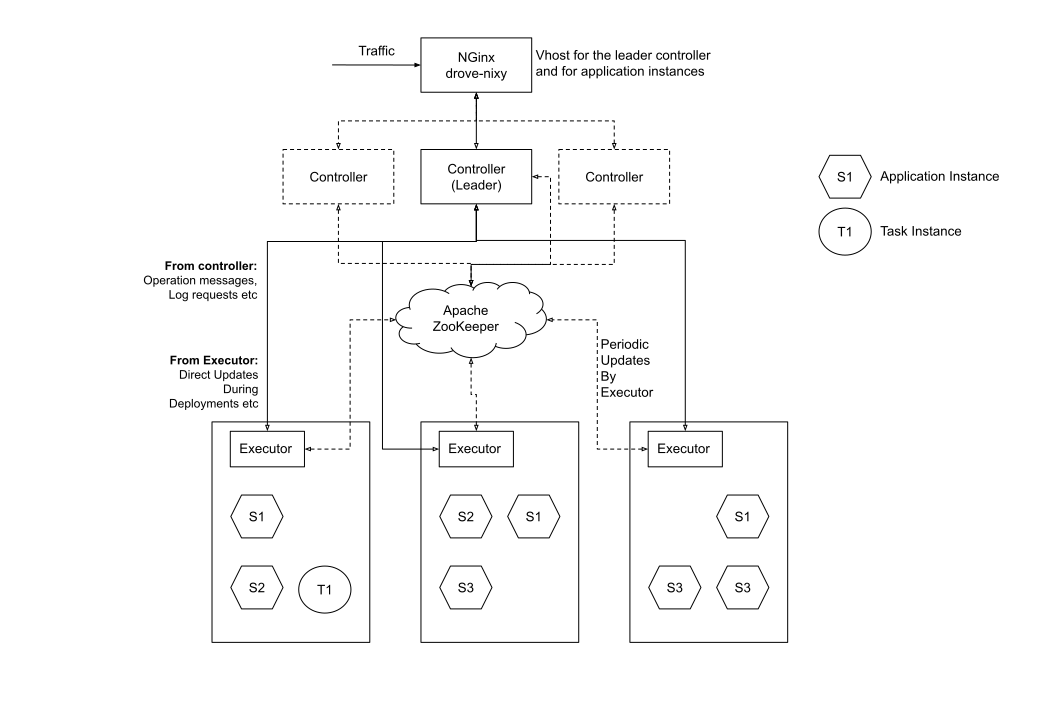 The overall topology consists of the following components:
The overall topology consists of the following components:
- An Apache ZooKeeper cluster for state persistence and coordination
- A set of controller nodes one of which (the leader) manages the cluster
- A set of executor nodes on which the containers actually execute
- drove-gateway + NGINX/HAProxy nodes that expose virtual hosts for the leader controller as well as for the vhosts defined for the various applications running on the cluster
Apache ZooKeeper¶
Zookeeper is a central component in a Drove cluster. It is used in the following manner:
- As store for discovery of cluster components like Controller and Executor to each other
- For electing the leader controller in the cluster
- As storage for Application and Task Specifications
- Asynchronous communication channel/transient store for real-time information about controller and executor state in the cluster
Controller¶
The controller service is the brains of a Drove cluster. The role of the controller consists of the following:
- Ensure it has a reasonably up-to-date information about the cluster topology and free/used resources
- Track executor status (blacklisted/online/offline etc) and tagging. - Take corrective actions in case some of them become inaccessible for whatever reason
- Manages container placement to ensure that application and task containers get placed according to provided placement configuration/spec
- Manage NUMA node and core affinity ensuring that instances get deployed optimally on cores and NUMA nodes without stepping on each other
- Provide a UI for users to consume data about cluster, applications and tasks
- Provide APIs for systems to provision apps, tasks and manage the cluster
- Provide event stream for other tools and services to follow what is happening on the cluster
- Provide APIs to list container level logs and provide real-time offset based polling of log contents for application and task instances
- Implement leader election based HA so that only one controller is active(leader) at a time.
- All decisions regarding scheduling, state machine management and recovery are taken only by the leader
- Manage the lifecycle of all applications deployed on the cluster.
- Maintain the required number of application instances as specified during deployment. This means that the controller has to monitor all applications running on all nodes and replace any instances or kill any spurious ones to ensure a constant number of instances on the cluster. The required number of instances is maintained as expected count, the current number of instances is maintained as running count.
- Provide a way to adjust the number of instances for this application. This would help in users being able to scale applications up and down as needed.
- Provide a way to restart all instances of the application. This would mean the controller would have to orchestrate a continuous string of start-kill operations across instances running on the cluster.
- Graceful shutdown/suspension of application across the cluster. This comes as a natural extension of the above and is mostly a scale down operation with the expected count set as zero.
- Manage task lifecycle
- Maintain task state-machine by scheduling it on executors and ensuring it reaches terminal state
- Provide mechanisms to cancel tasks
- Reconcile stale and dead instances for applications and tasks and take corrective measures to ensure steady state if necessary
- Application instance migration from blacklisted executors
- Send command messages to executors to start and stop instances with retries and failure recovery
Executors¶
Executors are the agents running on the nodes where the containers are deployed. Role of the executors is the following:
- Publish hardware topology of the machine to the controller on startup.
- Manage container lifecycle including:
- Pulling containers from docker repository with optional authentication
- Start containers with proper options for pinning containers to specific NUMA nodes and cores as specified by controller
- Data for an instance is stored as specific docker label values on the containers themselves
- Run HTTP call or shell command based readiness checks to ensure application container is ready to serve traffic based on readiness checks specification in start message
- Monitor application container health by running periodic HTTP call or shell command based health checks as specified by controller in start message
- Track normal (for tasks) or abnormal (for application instances) container exits.
- For tasks, the exit code is collected and used to deduce if task succeeded (exit code is 0) or failed (exit code is non-zero)
- For application containers, the expectation is for the container to stop only when explicitly requested and hence all exits are considered as failures and handled accordingly
- Stop application containers on request from controller
- Run any pre-shutdown hook calls as specified in the application specification before killing container
- Cleanup container volumes etc
- Cleanup docker images (if local image caching is turned off which is the default behaviour)
- Send regular local node status updates to ZooKeeper every 20 seconds
- Send instant updates by making direct HTTP calls to the leader controller when anything changes for any running containers and for every step of the container state machine execution for both task and application instances to allow for faster updates
- Recover containers on process restart based on the metadata stored as labels on the running container. This data is reconciled with a snapshot of the expected instances on the node as received from the leader controller at that point in time.
- Find and kill any zombie containers that are not supposed to exist on that node. The check is done every 30 seconds.
- Provide container log-file listing and offset based content delivery APIs to container
Executor states¶
Executor nodes in Drove move through the following states:
| State | Meaning |
|---|---|
ACTIVE |
Executor is healthy and can receive new workloads. |
UNREADY |
Executor is not ready for normal scheduling yet. This is used while node-level reconciliation/bootstrap is in progress. |
BLACKLIST_REQUESTED |
Executor blacklisting has been requested and migration is in progress. |
BLACKLISTED |
Executor is out of rotation and does not receive new workloads. |
REMOVED |
Executor has been removed from the cluster topology. |
Note
For normal scheduling, only ACTIVE executors are considered for new application/task placements.
Note
When an executor starts up or is brought back into rotation, it can remain UNREADY until required local service containers are reconciled and running on that node. Only after that does it move to ACTIVE.
Drove-Gateway with NGINX or HAProxy¶
Almost all of the traffic between service containers is routed via the internal Ranger based service discovery system at PhonePe. However, traffic from the edge as well and between different protected environments are routed using the well-established virtual host (and additionally, in some unusual cases, header) based routing.
- All applications on Drove can specify a Vhost and a port name as endpoint for such routing.
- Upstream information for such VHosts or endpoints is available from an API from the leading Drove controller.
- This information can be used to configure any load-balancer or tourer or reverse proxy to expose applications running on Drove to the outside world.
-
We modified an existing project called Nixy so that it gets the upstream information from Drove instead of Marathon. Nixy plays the following role in a cluster:
-
Track the leader controller for a Drove cluster by making ping calls to all specified controllers
- Provide a special data structure that can be used by a template to expose a vhost that points to the leader controller in a Drove cluster. This can be used for any tools that need to interact with a Drove cluster for deployments, monitoring as well as callback endpoints for OAuth etc etc
- Listen to relevant events from the Drove cluster to trigger upstream refresh as necessary
- Provide data structures that include the vhost, upstream endpoints (host:port) and metadata (application level tags) that can be used to build templates that generate NGINX or HAProxy configurations to enable progressively complicated routing of calls from downstream to upstreams hosted on Drove clusters. Data structure exposed to templates groups all upstream host:port tuples by using the vhost. This allows for multiple deployments for the same VHost to exist. This is needed for a variety of situations including online-updates of services.
- Supports username/password based authentication and header based (used internally) to Drove clusters.
- Support for NGINX (OSS/Plus) as well as HAProxy based gateway setups.
Tip
Gateway deployment is standard across Drove clusters, with NGINX or HAProxy as the proxy layer. For high-traffic clusters, the cluster exposing the VHost for Drove itself might be separated from the one exposing application virtual hosts to allow easier independent scaling.
Other components¶
There are a few more components that are used for operational management and observability.
Telegraf¶
PhonePe’s internal metric management system uses a HTTP based metric collector. Telegraf is installed on all Drove nodes to collect metric from the metric port (Admin connector on Dropwizard) and push that information to our metric ingestion system. This information is then used to build dashboards as well as by our Anomaly detection and alerting systems.
Log Management¶
Drove provides a special logger called drove that can be configured to handle compression rotation and archival of container logs. Such container logs are stored on specialised partitions by application/application-instance-id or by source app name/ task id for application and task instances respectively. PhonePe’s standardised log rotation tools are used to monitor and ship out such logs to our central log management system. The same can be replaced or enhanced by running something like promtail on Drove logs to ship out logs to tools like Grafana Loki.